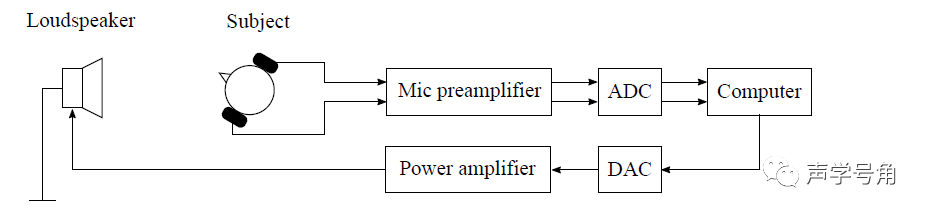
从声源到声音感知和房间中的声音传播
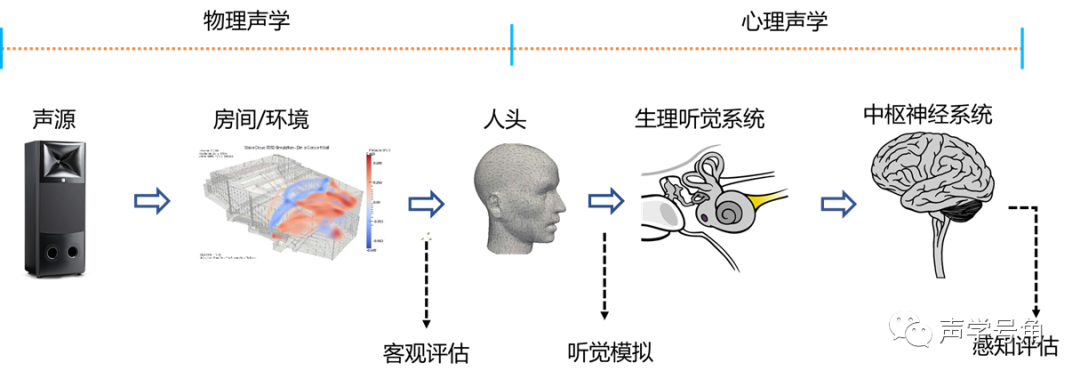
本文首发于微信公众号「声学号角」 完整的声音感知过程: 扬声器或者其他产生一个声源,声音通过房间/环境传播,绕过人头传入双耳,并听过生理听觉系统和中枢神经系统,从而感知到声音信号。分别牵涉到物理声学和心理声学。 人头相关模型的传递函数可以将声压场转换为双耳响应。 声源方向,房间/环境的几何形状,边界条件,头部尺寸和形状,听觉系统等都会对最终的声音感知造成影响。可以分别单独考虑,也需要整合起来一起考虑。 大多数实际情况下,房间可以看成线性时不变系统,其空间传递函数可以使用脉冲响应RIR作为特征。 一个1700m^3小型音乐厅的声学测试结果。其中声场的直接能量标记为黑色,早期反射能量标记为蓝色,蓝色之后的渐变属于混响场的建立过程。 房间脉冲响应: 时间包络曲线: RIR只是声压的评估,本身并不携带关于声场方向性的信息。 外围生理听觉系统简化示意图: 声波通过耳廓,传到耳道,振动鼓膜。鼓膜推动锤骨-砧骨-镫骨,再将振动传递到耳蜗,从而转换为神经电信号,通过听觉神经传入大脑。 耳道是一个不规则形状的管,其平均尺寸大约是水平方向6.5mm,垂直方向9mm,长度约25mm到35mm。其谐振频率约在2-5kHz范围内。 人体耳道的声学特性【Comsol新案例】 耳蜗的横截面:人的听觉系统组成部分很多,还是比较复杂的 RIR描述的是空间两个位置之间的传递函数。如果是人在听音,那么实际上有两个脉冲响应应该考虑,通常被称为双耳脉冲响应Binaural Impulse Response (BIR)。当在房间中测量时,被称为Binaural Room Impulse Response (BRIR)。 人头在声场中对声场分布的改变:220Hz,600Hz,1400Hz 水平定位主要通过双耳时间差(ITD),双耳声级差(ILD)。 人听觉系统的单声源定位 当然还有不同方向入射的声源频谱因素 HRTF和BIR是等效的。下图是45°是左右耳的BIR响应: 对室内声场进行建模,一般可以通过射线追踪,或者波动声学进行求解计算。 下图是一个音乐厅的离散化模型。 人头的离散化模型 射线追踪,一般用于中高频,对低频的一些波动和衍射等现象计算准确度不够 波动声学可以采用时域有限元法FETD,但计算量会比较大。用时域有限差分法FDTD,或间断有限元DG,比较多。 室内声场的动态波动仿真建模 仿真在自由场和场景中存在障碍物声传播的差别 室内的声场仿真和研究对改善现有音箱产品的体验,以及后续的VR/AR都是很关键的。